利用邊緣技術Kafka對接福建省綜合能源公司平台成功運行
在邊緣技術領域,那些從事制造業、自動化行業、航空、物流、以及零售等行業應用的開發人員經常會思考的一個問題是:到底應該在邊緣處,還是應該在“真實”的數據中心、或是在公共雲基礎架構中部署Apache Kafka?
在本文中,我們将向邊緣計算領域的開發者介紹Kafka在物聯網(IoT)邊緣處的不同用例和架構用法。文末,我們還會讨論Kafka作為事件流平台,是如何在邊緣處對其他IoT框架及産品進行補充,進而實現大規模的實時數據集成與邊緣處理。
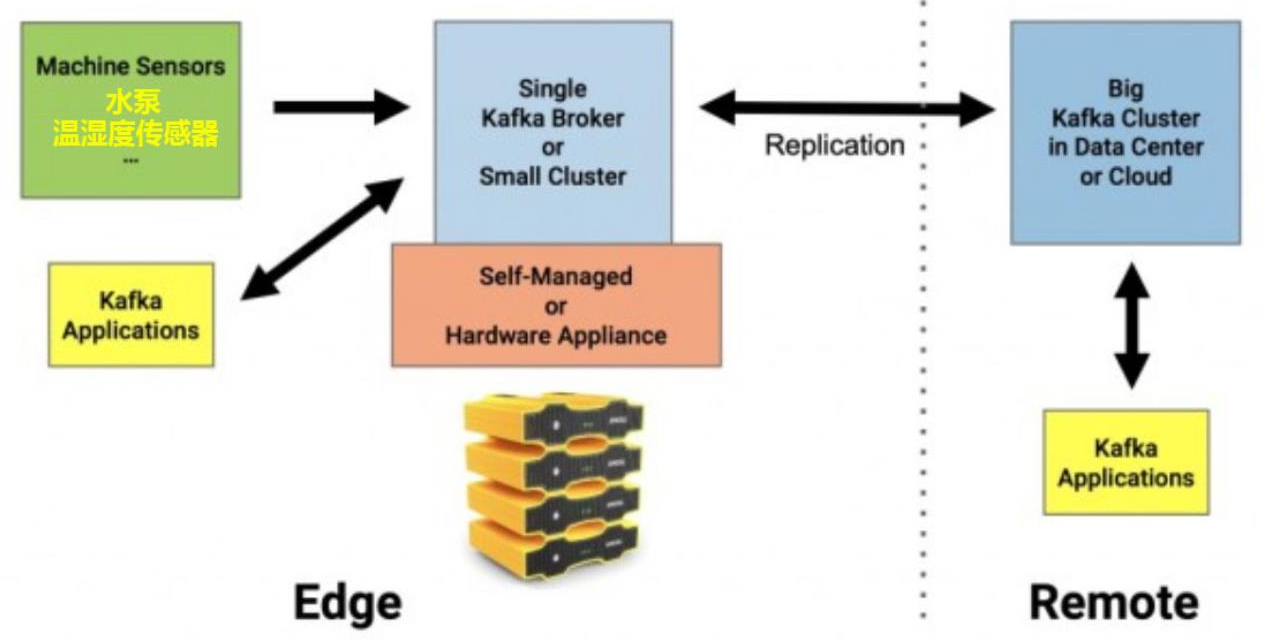
常态化的多個Kafka群集
如今,Apache Kafka的多集群和跨數據中心的部署方式,已成為了業界的某種規範。雖然“邊緣處Kafka(Kafka at the edge)”可以被部署為一個獨立的項目;但是在大多數情況下,它處于整個Kafka架構中的一部分。許多企業會根據如下原因,來創建多個Kafka集群:
- 獨立的項目需求。
- 混合式的集成方法。
- 邊緣計算。
- 組件聚合。
- 平台移植。
- 災難恢複。
- 區域或洲際通信所需的全球架構。
- 跨企業之間的溝通。
維度電氣的邊緣處Kafka的用例
福建省綜合能源接入背景
根據安全防護方案要求,維度主站CPS系統需要通過安全接入網關實現安全接入互聯網大區,根據與聯研院安全接入網關項目組溝通,
安全接入網關可以提供基于X86架構的安全接入組件,将該組件部署在維度主站CPS系統主機上,可以實現安全接入。
總體架構如圖
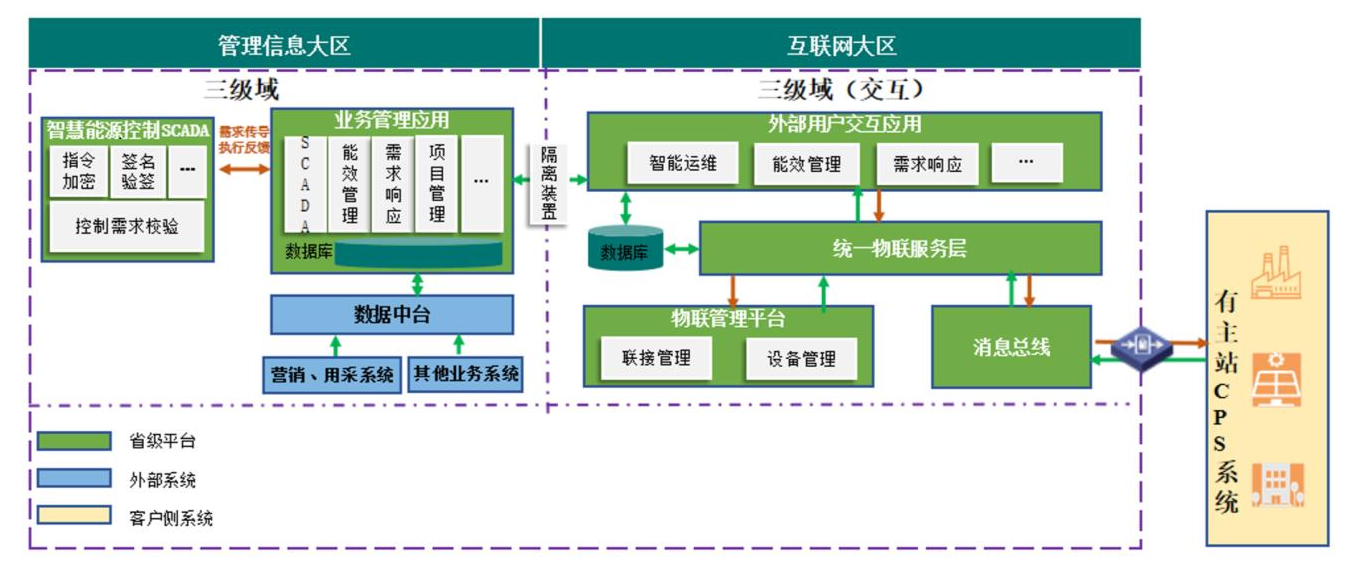
維度接入方案
1.維度主站CPS系統設備檔案上送至智慧能源服務平台(CPS系統整理,省級平台導入)
2.智慧能源服務平台需要維護維度主站CPS系統設備檔案以開展相關業務,維度主站CPS系統将檔案按照省級平台的要求生成Excel表格,由平台運維人員進行頁面配置或者導入操作。
3.維度主站CPS系統主機安裝安全接入組件(省級平台提供,CPS安裝測試)
4.維度主站CPS系統上報采集數據(CPS系統改造上報)
5.省級平台從消息總線訂閱采集數據,并對數據進行處理、存儲等操作,供業務系統使用。
6.維度主站CPS系統接收控制策略信息
程序開發與部署
1.程序以Java為主要開發語言,以JAR包發布。
2.通過更改配置文件即可達到靈活支持不同業務功能。
3.可以部署到SystemD或容器中,增加了彈性部署能力。
4.實現了設備層與數據層之間的解耦。
5.能夠有效地處理背壓(back-pressure)。
6.即使隻有一個客戶端,也能實現實時地處理大容量數據。
7.在磁盤上進行存儲,能夠重新處理數據。
8.修改的日志級别:為了減少線上日志大小,并能切換開發環境和線上環境。
服務運維
1.SystemD或容器結合程序信号機制,監視程序運行狀态,保證了程序以7*24正常地運行着
2.運維監控數據:分日期和小時記錄,方便定期歸檔
3.運維監控數據:記錄錯誤時的調用棧:當出現fatal和error級别的錯誤時,有時隻靠錯誤信息時很難準确定位到錯誤代碼的,所以需要記錄函數的調用棧,方便排查錯誤
4.運維監控界面:提供前端網頁查詢實時系統運行狀态,方便了解掌握系統運行情況
關注維度
Follow

微信公衆号
- 新浪微博
- 騰訊微博
- 騰訊QQ